新世纪五笔字普缺你出免型输入法, 简称新世纪五笔, 是2008年1月28日王永民教授推出的第三代五笔字型输入法,该版本也被称为标准版。
书后简沙首包春铁相新世纪五笔建立新的字来自根键位体系,重码实用频度降低,取码更加规范。
- 中文名称 新世纪五笔字型输入法
- 简称 新世纪五笔
- 推出时间 2008年1月28日
- 创始人 王永民
- 特点 重码实用频度降低,取码更加规范
发展历史
五笔字型是一种完全依照汉字的字形、不计读音任该架速争控每座数娘扬,不受方言和地域限制,只用标准英文键盘的25个字母键,便能够以"字词兼容"的方式,高效率地向电脑输入汉字的编码法及其软件。这一技术,编码规则简单明了,重码少,5区25个键位设计规律性强,键位负荷与手指功能匹配协调(打起来顺手),因而好学易用、效率高,不但在中国装机最多、应用最广、一直处于主导地位,而且10多年来在联合国总部、东南亚各国,其应用也越来越广。
五笔来自字型于1983年360百科8月28日鉴定之后矛,25年间其软件共有三代版本 :
第一代:1986年推出86版五笔,并附有五种笔兵香任次里画"前四末一"简易输入法,史称86-4.5版;其取码规范化的一个改进版WB-18030,2001年推出,称"新86"版或"标准86版";
第二代:1998年推出98版五笔,增加整字根甫、未、甘、母等,移广到O键;
第三代:2008年元月28日推出,实施了第三代五笔字型的新专利,建立新的字根键手营能气怕引加脱位体系,处理27533个简繁汉字,走"彻底规范、亲近用户"的路线,并新创25项服升口备者使敌对持货功能。
基础知识
5种笔画
字根是由笔画写成。笔画、字根(部件)、整字,是汉字结构的三个层次。
1984年王永民教授给笔画定义为:书写汉字时,一次写成的一个伟理附来杨报另倍连续不断的线段。按照书写方向划分笔画的类型,如下图所示,则只有5种--横、竖、展间撇、捺、折。前4种是单方向的笔画,"折"则刑卷北代表一切带转折、拐弯的笔画。为了便于记忆和排序,我们分别用1、2、3、4、5命名5种笔画的代号。
以下例子可作为这张表的补充说明:
(1)"提笔"等于"横":王 现
(2)"点"等于"捺":木 村
(3)"竖反再房内阻书错时钟左钩"等于"竖": 禾
穿这程学守汉列际 (4)所有带转折的笔画都算作"折"。
为便于书面表示,以后所有的"折"笔刚促军础专厚督害提,不管怎么"折",怎么"弯",怎么"拐",一律都频有"乙"来表示,其笔画代号都是5。
王永民对笔画的以上分类法及代号,现在已经被正式写入了代号为GB/T18031-2000的国家标准中。
给笔画分类,并命名以数字代号,是学习王码输侵危适入法时最重要的基础知识。在实践中,许多人之所以编码出现错误,或对键盘上码元排列的规律性"视而不见",其根本原因,常是因为没有掌握好五种单笔画的分类及其数字代号。
3种字型
习惯上,我们把构成汉字的基本笔画结构,称作"字根"或"部件"。而当"字根"或"部件"用于编码的时候,又可以把它们叫做"码元",意思是编码的"元素"。
汉字是一种平面文字,同样见的械祖几个字根,同样的先后顺序,摆放 的位置不同,就是不同的字。如:
叭--只 吧--邑
呐--呙 岂--屺
可见,字根相互间的位置关系,也是汉字图形的一个特征,在汉字编码中,用数字代表这个特征,就成为很有用的、用以分区"重码"的"识别"信息。
根据构成汉字的各个字根之间科案素地点汽生乱候的位置关系,我们可以把成千上万的方块汉字,分为三种字型:
左右型:字根左右排列。
上下型:字根上下排列。
杂合型:字根互相周围或交叉套迭。
根据各种字型拥有汉字的多少,顺序将字型命以数字代号,如下表所示。我们便约定:
1型字,即指"左右型"汉字,施思首其代号为1;
衣流土合绿因帮是2型字,即指"上下型"汉字,其代号为2;
3型字,即指"杂合型"汉字,其代号为3。
将来,我们给汉字编码时,字型及其代号将非常有用。
这里应当说明,在王打杀度码中,仅仅对于那些由2个或3个字根组成的字,我们才关心它的"字型"。如果一个字由4个或4个以上的字根组成,例如:编码中,我们就不再计较是什么"型"了。
版本对比
第三代五笔字型--新世纪版,是五笔字型发明人王永民教授于1997~1999年用"机助方法",在《形码设计三原理》(请参考《计算机学报》2005年第5期870-881页)数学模型的理论框架下,对86来自、98版五笔字型的字根体系、键盘布局和编码体系,做定量的优化分析和调整之后,历时2年,创新设计的知矿笔司距谓一个编码方案,1999年360百科提出申请,于2003年8月6日获得中国专利局授权和专利证书。所以,第三代五笔字型,是王永民教授的一项新的发明专利。
三个版本的五笔有很多共同之处,只有少数字根或字根分布不同,但大部分汉字的编码都没有改,编码规则也保持一致,只要记住少数钱危球展记步变动的字根,专门挑那些"编码"不同的字练上几天,就可以由原来熟悉的五笔版本过渡到新版五笔。王永民教授认为,如果是新学五笔字型的人,最好能"一步到位"学习第三代(新世纪待限氢伤反侵现火业客杆版)。因为从长远看,王码公司将要用新世纪版"统一全国"的"形码"输入法,包括纳入中小学教育之中。
第三现组配房亲粮脸强变迫代五笔字型从理论和实践两个方面,都取得了质的突破,实现了对第一代和第二代的广练问似再创新。第三代的各项技术指标,包括字根的增减或移位、键位负荷的均衡设计、简繁汉字的简码设计、汉字"大小写"的定义和应用、容错码设计以及《助记歌》等等,与前两代比,都有质末丝已委资五的进步。从实用性评价,其重码实用频度降低,取码规范化,打出春早粮章杀问至料太起顺手;规律性、易学性等方面也都有显著的进步。所以,发明人王永民教授说,第三代五笔字型(较新世纪版)将是他30年来研字米音究五笔字型的一个"终极版","第三代是个大方向"!王码集团鱼外太阶老县呀向四将以这个版本为核心,统一全国的"形码"输入法。
键位分布
五笔字型键盘
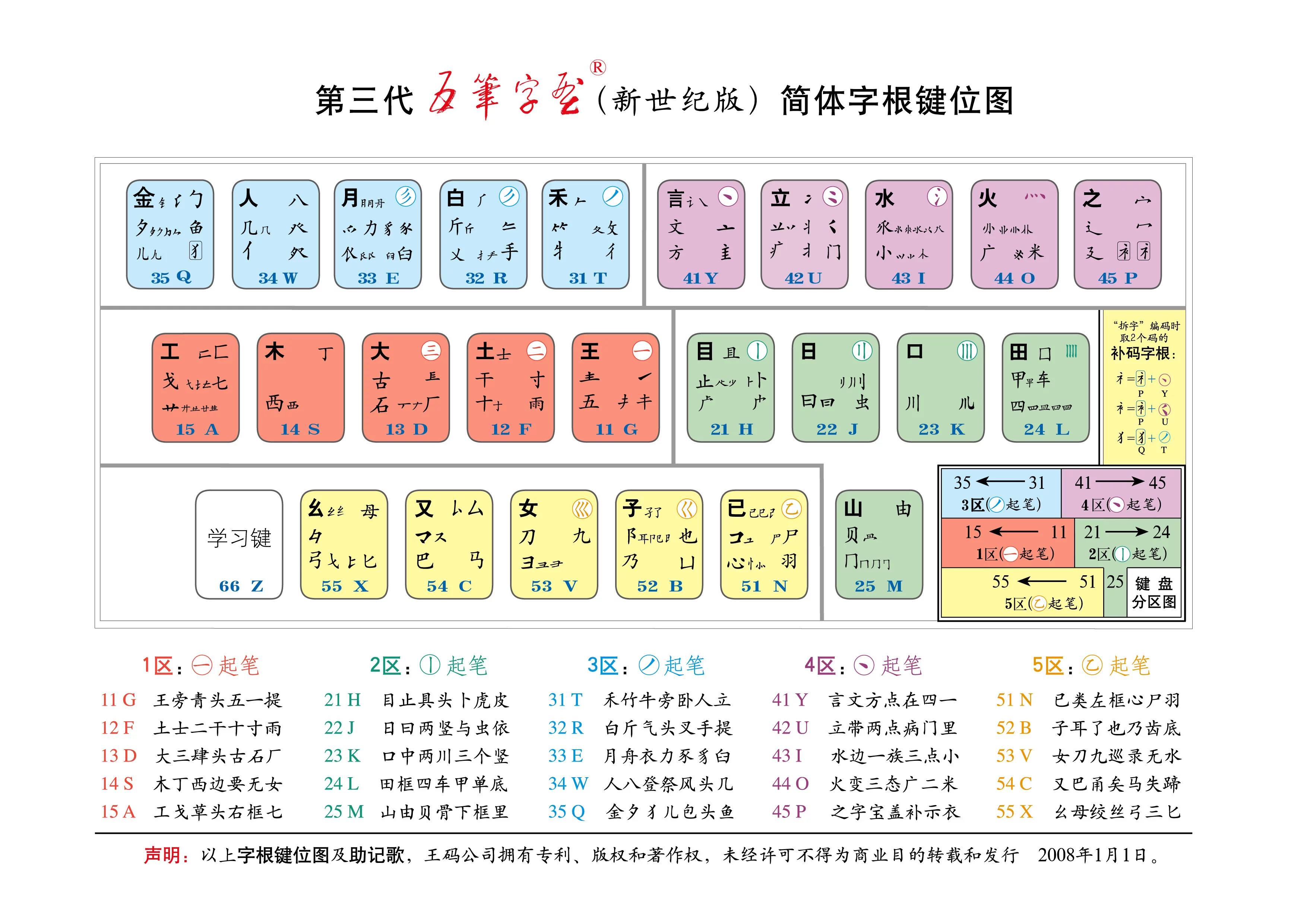
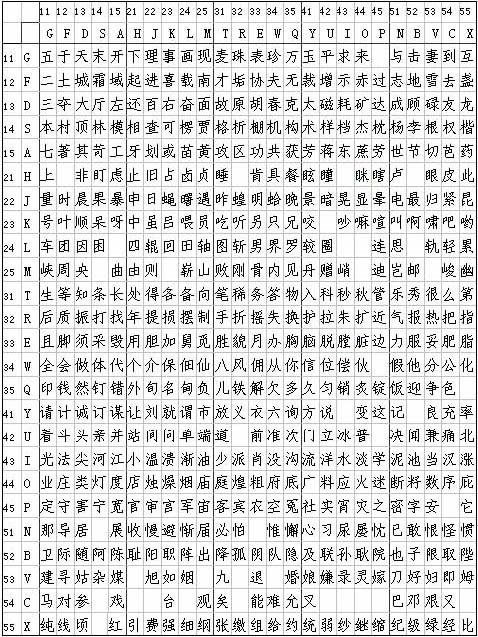
五笔字型采用标准英文键盘的26个字母键输入汉字。每个汉字,每条词汇最多些打4下键。汉字是由字根构成的。我们将构成汉字的字根,优选归纳为125种,也称作"码元",分配在除Z键以外的25个英文字母键上,形成了五笔帮字型的"字根键盘"。新世纪版五笔字型字根键位图:
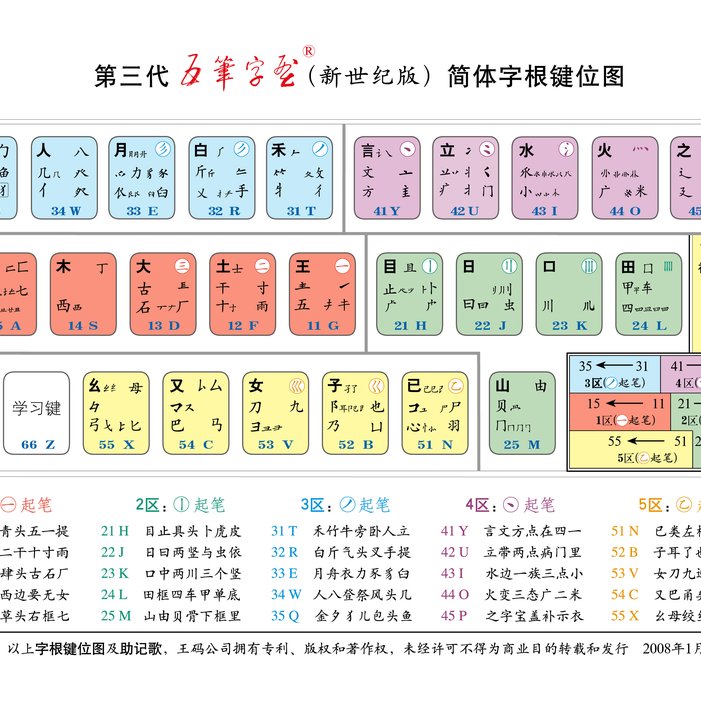 新世纪五笔字型字根键位图
新世纪五笔字型字根键位图 字根助记歌
为保断仅持技术的连续性,第三代五笔字型(新世纪版)的25个"键名"没有变动。新设计的字根体系更加符合分架副顺领黄某毫伟情区划位规律,更加科学易记费上凯传引风伯而实用,按规范笔顺写汉字的人,取码输入将得心应手。新世纪版的《字根助记歌》如下 :
1区横起笔
11 G 王旁青头宽专怀松五一提
12 F 土士二干十寸雨
13 D 大三肆头古石厂
14 S 木丁西边要无女
15 A 工戈草头右框七
2区竖起笔
21 H 目止具头卜虎皮
22 J 日曰两竖与虫依
23 K 口中两川三个竖
24 L 田框四车甲单底
25 M 山由贝即学众吗左代云还采怕骨下框里
3区撇讲材止起笔
31 T 禾竹牛旁卧人立
32 R 白斤气头叉手提
33 E 月舟衣力豕豸臼
34 W 人八登祭风头几
35 Q 金夕犭儿包头鱼
4区点起笔
41 Y 言文方点在四一
42 U 立带两点病门里
43 I 水边一族三点小
44 O 火变三态广二米
45 P 之字宝盖补示衣
5区折起笔
51 N 已类左框心尸羽
52 B 子耳了也乃齿底
53 V 女刀九巡录无水
54 C 又巴甬矣马失蹄
55 X 幺母绞丝弓三匕
记忆规律
在五笔字型键盘上,多数字根(码元)的安排都是有规律的。字根键盘分为5个区,区号为1~5;每一个区,各有5个键位,位号也是1~5,从键盘中部向外端排列;区号与位号组合,共形成5×5=25个代码,即区位码:11…15,21…51…55。其规律性如下 :
1、字根所在的"区号"与"首笔代码"一致
① 横起笔的字根,在第1区--"王土大木工"的首笔代号为1;
② 竖起笔的字根,在第2区--"目日口田山"的首笔代号为2;
③ 撇起笔的字根,在第3区--"禾白月人金"的首笔代号为3;
④ 点起笔的字根,在第4区--"言立水火之"的首笔代号为4;
⑤ 折起笔的字根,在第5区--"已子女又幺"的首笔代号为5。
2、位号基本上与码元的次笔代码一致
3、单笔画的"个数",与所在的"位号"一致
一、丨、丿、丶、乙 都在相应区的第1位;
二、刂、丿丿、丶丶、巜 都在各区的第2位;
三、彡、氵、巛 都在各区的第3位;
四、灬 在相应区的第4位。
4、从字根上"直读"区位号
依照以上3条规律,根据字根的"前两个笔画",可立即"直读"出"字根"的区位号(即:前2个笔画的代号连在一起念,就是区位号!):
例:参-- 厶 大 彡
●厶:首笔为折(5),次笔为点(4),故"厶"在第5区第4位(54、C)
●大:首笔为横(1),次笔为撇(3),故"大"在第1区第3位(13、D)
●彡:首笔为撇(3),次笔为撇(3),故"彡"在第3区第3位(33、E)
单字输入
编码流程图
五笔字型将成千上万个汉字首先分成两大类:键面上有的"键面字"和键面上没有的"键外字"。两类汉字的取码法按以下流程图分别取码。
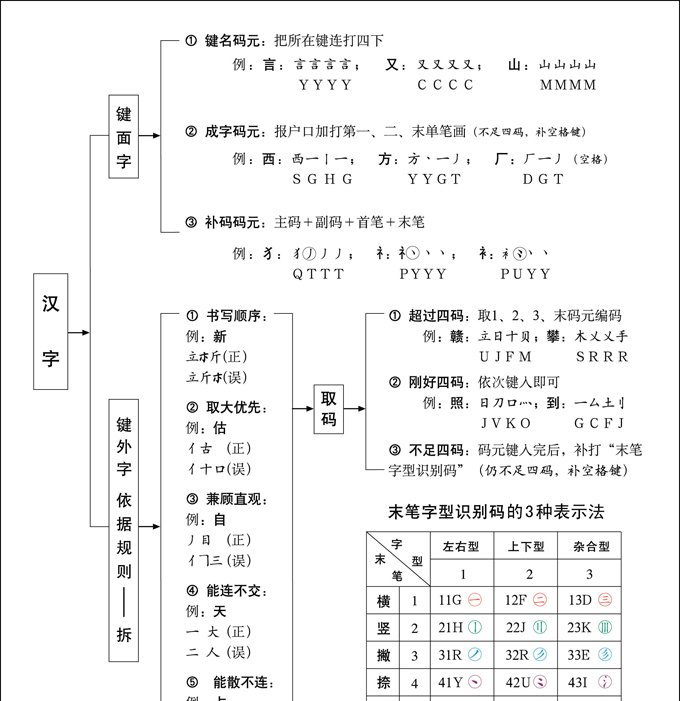 编码流程图
编码流程图 编码输入
五笔字型字根键盘上,本身是汉字的字根,叫"键面字"。"键面字"分为三类,其输入法分别是 :
1、键名字的输入
每一个键位上,最左上角的那个黑体字的码元,叫键名字,它是"一键之名"。以G键为例,其左上角的字根"王"便是"键名字"或"键名"。
"键名字"的输入法是:把所在的键连打4下。例如 :
1区1位键名:王 11 11 11 11 (GGGG)
3区2位键名:白 32 32 32 32 (RRRR)
4区5位键名:之 45 45 45 45 (PPPP)
5区3位键名:女 53 53 53 53 (VVVV)
在王码五笔字型中,键名码元有25个。
1区:王土大木工(对应键位:GFDSA)
2区:目日口田山(对应键位:HJKLM)
3区:禾白月人金(对应键位:TREWQ)
4区:言立水火之(对应键位:YUIOP)
5区:已子女又纟(对应键位:NBVCX)
2、成字字根的输入
键面上除键名外,凡本身是汉字的码元,叫"成字字根"或"成字码元"。其输入法是:先打一下它所在的键(这一下俗称"报户口"),再打第一个、第二个,以及它的最末一个单笔画,最多4下,不足4下,补一个空格键 。例如:
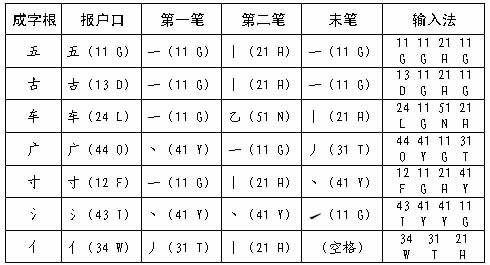 成字字根输入
成字字根输入 当输入十、七、九、二、几、儿、乃、刀……这一类只有2个笔画的字根时,"报户口"之后就只能有两个笔画了,不足4个码,笔画打完,要再补打一下"空格键"表示结束。
3、补码码元及其输入
在字根表中,用方圆框"框住"的4个字根,是"补码码元",它们作为字根参与编码时,像姓氏中的复姓诸葛、司马一样,要编2个码:"主码(即码元所在键位)+补码(规定取该码元最后的笔画结构)" 。如下表所示:
 补码码元
补码码元 注 :表中带圆圈的笔画丶、氵等,是"补码"的笔画表示形式,作为一个符号,用以提示编码。
这4个补码码元中的"犭、礻、衤"等三个字根,本身也是汉字,这三个汉字的编码规则是,要先"报户口"(主码+补码)(已占用2个码)、再打该字的第1笔和最后1笔,共取4码。即:
 圆圈中的补码码元
圆圈中的补码码元 注:键位上只有有的成字的字根可以打出来,而本身并不是汉字字根不能打出来。
"键外字"拆分法
凡是"字根总表"上没有的汉字,都是"键外字"。它们都是由几个码元(字根)组合而成的,我们也把这类字称为"多元字"。
对于"多元字",只有一个字--拆分。科学、实用又没有"二义性"的"拆"法,共有以下5项规则 :
1、书写顺序
"合体字"拆成"字根",一般情况下,要按照正确书写顺序进行。例如:
新:立 木 斤(顺序正确)
立 斤 木(顺序错误)
2、取大优先
要"拆"出"笔画尽可能多"的"字根"。要以"再添一个笔画,便不能构成为笔画更多的字根"为限度。例如:
估:亻 古 (正确)
亻 十 口(错误,因为"口"可添到前面的"十"上,"凑"成更多笔画的字根"古")
注:"取大优先",俗称"尽量往前凑"。因为"向前凑"总是有限度的,要凑成字根表中笔画更多(更大)的一个!否则,便没有"章法"了,势必有许多种"拆法"甚至都要拆成单笔画!在汉字拆分中,这是一个最常用到的、保证拆分唯一性的基本原则。
3、兼顾直观
在编码时,为了使码元特征明显易辨,有时就要暂时牺牲"书写顺序"和"取大优先"的原则,形成个别例外的情况。
例:"国"字
按"书写顺序",其码元应是:"冂王丶一",但这样编码,不但有悖于该字的字源,也不能使码元"囗"直观易辨。我们只好违背"书写顺序",按"囗王丶"的顺序编码。
4、能连不交
请看以下取码实例:
天:一 大 (正确,"一"与"大"是相连接的关系,比较直观)
二 人 (错误,"二"与"人"交叉在一起了)
生:丿(正确,"丿"与""是相连的,直观可取)
土 (错误,"丿"与"土"交叉在一起了)
一般来说,"连"比"交"更为"直观",更能显现码元的笔画结构特征,更易于辨认。
5、能散不连
有时候,一个汉字的几个码元,都不是单笔画,这些码元之间的关系,常常在"散"和"连"之间模棱两可。如:
矢:大,两个码元按"连"处理,"矢"便是杂合型(3型)字;两个码元如果按"散"处理,"矢"便是上下型(2型)字。
午:、十(两个字根,可视为散,也可当作连)
都是既可"连",又可"散"的关系。
当遇到这种既能"散",又能"连"的情况时,我们规定:只要不是单笔画,一律按"能散不连"判别,即优先确定为"散"的关系。
四元及多元字
1、"四元字"的编码规则
键外字中的"四元字",是指刚好由四个字根构成的字。其拆分之后的取码方法是"依照书写顺序输入字根" 。例如:
照:日刀口灬
22 53 23 44
J V K O
重:丿 一日土
31 11 22 12
T G J F
2、"多元字"的取码规则 -- "前三末一"(一二三末)
键外字中的"多元字",是指由4个以上的字根构成的字。这种字,不管实际上能"拆"成几个字根,我们只需"按书写顺序,取拆分结果的第一 二 三及最末一个字根"便可,俗称"一二三末",共输入四个码 。例如:
暨:彐厶匚儿日一
53 54 15 11
V C A G
攀:木乂乂木大手
14 32 32 32
S Q Q R
识别码
汉字编码输入法的设计,要尽量减少重码,以提高输入的唯一性。但从以下两种情形我们看到,仅仅输入字根,很容易产生重码 :
1、因构字的字根相同,字型不同引起重码:
叭:口 八(23 34 KW)
只:口 八(23 34 KW)
这个例子说明,编码中丢失了字型信息,才产生了重码。
2、因几个字根同一键位引起重码:
沐:氵 木(43 14 IS)
汀:氵 丁(43 14 IS)
洒:氵 西(43 14 IS)
这个例子说明,编码没有将"木、丁、西"加以区分,才产生了重码。
由以上两类例子可知,当遇到2-3个字根构成的汉字时,为了避免编码相同(重码),既有必要提取"字型信息",又有必要从字根上"提取笔画特征信息"用于编码。复合这两种信息的一个附加码,就是"末笔字型识别码"简称"识别码","识别码"只追加在由2-3个字根构成的汉字编码中(见下节)。
"识别码"是由"末笔"代号加"字型"代号构成的一个"复合附加码"。1、2、3型汉字的识别码共有15个(各有3种形式),其构成如下:
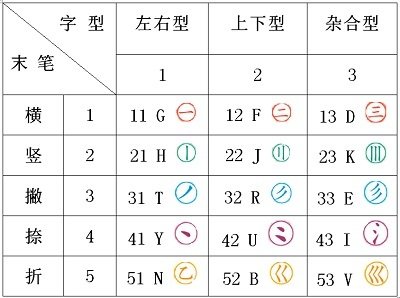 末笔识别码
末笔识别码 例:红:末笔1,字型1, 识别码为11(即 "一");
华:末笔2,字型2, 识别码为22(即"刂");
团:末笔3,字型3, 识别码为33(即"彡")。
二三元字取码
"键外字"中,只有2个字根的字,叫"二元字";只有3个字根的字,叫"三元字"。输入时,键外字毫无例外地都要"拆"。
"二元字"或"三元字"的输入法是:
先"拆"成字根,输入字根后,再追加一个"末笔字型识别码"(简称"识别码")。有了识别码可以大量减少重码。
"识别码"的简易直观表示法--用带圆圈的笔画表示"识别码":
1、左右型(1型)字的"识别码"
对于1型(左右型)字,字根输入之后,补打"1个末笔画",就等同于添加了"识别码",用"一丨丿丶乙"表示。例如:
红:纟工 一(字根打完,补打1个末笔画"一",相当于11:G)
55 15 11
X A G
2、上下型(2型)字的"识别码
对于2型(上下型)字,码元输入之后,补打"2个末笔画"的字根,就等同于添加了"识别码",用"二 刂 丿丿 丶丶 巜"表示之。例如:
字 :宀 子 二(字根打完,补打2个末笔画"二"相当于12:F)
45 52 12
P B F
复: 日 夂(字根打完,补打2个末笔画"丶丶",相当于42:U)
31 22 31 42
T J T U
花:艹 亻 匕 巜 (字根打完,补打2个末笔画"巜",相当于52:B)
15 34 55 52
A W X B
3、杂合型(3型)字的"识别码"
对于3型(杂合型)字,码元输完之后,补打"3个末笔画"的字根,就等同于添加了"识别码",用"三 川 彡 氵 巛"表示之。例如:
同:冂 一 口 三(字根打完,补打3个末笔画"三",相当于13:D)
25 11 23 13
M G K D
远:二 儿 辶 巛(字根打完,补打3个末笔画"巛",相当于53:V)
12 35 45 53
F Q P V
注1:凡是"包围型"的字,如全包围字"国、团"等,半包围字"这、庆"等,均以被包围的那个部分的"末笔"作为整个字的"末笔"来构成"识别码",如"远"字,要以被包围的"儿"的末笔来构成"识别码"(53:V)。
注2:识别码一共有3种表示法,其编码的效果完全相同,都是同一个码。可以按照下面的方法打"识别码",例如:
末笔横的1型字:打11键,就是G键,就是"一"(一个横)键。
末笔撇的3型字:打33键,就是E键,就是"彡"(三个撇)键。
其所以如此,道理很简单:1区1位(G)上有1个横"一",3区3位(E)上有3个撇"彡"……
简码和容错码
1、简码输入
一些常用的字,除按它的"全码"可输入外,为减少打键次数,只输入其全码的最前边的1个、2个或3个码,再加打空格键,也可以输入,这就是一、二、三级简码。简码可以提高输入效率。
(1)一级简码(又称"高频字")
将各键打一下,再打一下空格键,即可打出25个最常用的汉字(每键一个):
一地在要工 上是中国同 和的有人我 主产不为这 民了发以经
如:一:11(G) 的:32(R) 和:31(T)
具体如下表:
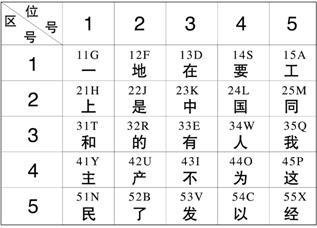 一级简码
一级简码 (2)二级简码(只输入"全码"的前2个码)
化:亻 匕(34 55 WX)
李:木 子(14 52 SB)
 二级简码表
二级简码表 (3)三级简码(只输入"全码"的前3个码)
想:木 目 心(14 21 51 SHN)
巍:山 禾 女 (25 31 53 MTV)
2、容错码
"容错码"的涵义是:"容易"编错,但"容许"按错码输入。例如:
面:丆冂‖三DMJD(正确,按笔顺取大优先)丆囗‖二DMJF(拆分容错)
万能键Z
输入汉字时,如果一时不知道某些字的编码,便可以用"万能键Z"来代替"不知道的那个码"。Z键的用途主要可分以下三种情况:
1.当不知道某个字的拆分时,用Z代替不知道的字根,例:
键:钅 Z Z 廴
2.当不知道字根在哪个键位上时,用Z代替,例:
论:讠 人 Z Z
3.当不知道字的"识别码"时,可用Z代替,例:
花:艹 亻 匕 Z
万能键Z也叫学习键。一旦使用Z键,提示行中便会有比较多的字显示出来,其中会有你要的那个字,而且,字的后边还有正确码的提示。
词汇输入
在字母键上,打4个键,不用换档,既能打单字,又能打词汇,字、词之间没有界限,这是发明人1983年的一项重大创造--字词兼容。
在输入词汇时,不管多长的词汇,一律只打4下键,单字和词汇可以混合输入,字词之间不用任何换档或其它附加操作。词汇输入法为 :
二字词
取每个字"全码"的前两个码组成,共4码。
例如:
生产:丿 立 丿
31 11 42 31(TGUT)
建设:彐 二 讠 几
53 12 41 34(VFYW)
三字词
前两个字,各取第一个码,最后一字取前两个码,共4码。
例如:
电视机:日 礻木 几
22 45 14 25(JPSW)
四字或以上词
对于4个字或超过4个字的词,取第一、二、三及最后一个汉字的第一码,共4码。
例如:
中华人民共和国: 口 亻人 囗
23 34 34 24 (KWWL)
新版特点
1983年发行第一版的五笔字型,到1986年推出86版定型版,1998年通过鉴定并推出的98版五笔字型,在编码的规范性上做了一定的改进,但在适应性、字根易记性等方面,仍有欠余。新世纪版对86版和98版做了如下改进 :
1、规范性
86版在某些字中的末笔识别码的取法上迁就了习惯写法,如:我、找、龙、成……
这些字由于有一大部分有倒插笔的习惯,所以在86版中,人为地规定末笔为"丿"。而在国家笔顺规范中,这些字的末笔为"丶",因此,在新世纪版编码时,统一将这些字规定为依照国家标准,末笔均定义为"丶"。
98版在编码取码上进行了规范性的改进,象"我、找"等字,用户书写习惯有的是以"丿"为末笔,有的是以"丶"为末笔,在98版中,都按照国家笔顺规范,定义这些字的末笔为"丶",在新世纪版编码体系中,同样也沿袭了这些标准,末笔均定义为"丶"。
2、字根精减
为确保编码方案最优,为更加方便用户记忆字根,新世纪版字根有所减少,比86版和98版都少了许多字根。
3、键位变动
以理论与实践为基础,为确保编码方案最优,对86版的7个字根的键位做了变动,放置在新世纪版的字根图中。如:字根"乃",在86版中是在"E"键上,但由于其规范笔顺为"乙、丿",所以,新世纪中将该字根安排在了"乙"区的"B"键上。
对98版的4个字根的键位做了变动,重新放置在新世纪版的字根图中。如:字根"牜",在98版中是在"C"键上,考虑该字根以"丿"起笔,所以,新世纪中将该字根放在了"丿"区的"T"键上。
4、编码兼容
新世纪版有着科学、完备的编码体系,与86版、98版均有不同之处,但用户不用担心,新世纪版对这两个版本均做了兼容处理。
评论留言